让不懂建站的用户快速建站,让会建站的提高建站效率!

转自:财联社
《科创板日报》12月11日讯(裁剪 宋子乔)日前,加州大学相关东谈主员和英伟达共同发布了新的视觉言语模子“NaVILA”。亮点在于,NaVILA模子为机器东谈主导航提供了一种新有操办。


NaVILA模子的有关论文
视觉言语模子(VLM)是一种多模态生成式AI模子,好像对文本、图像和视频教导进行推理。它通过将大言语模子(LLM)与视觉编码器相麇集,使LLM具有“看”的智商。
传统的机器东谈主活动时常依赖于事前绘图的舆图和复杂的传感器系统。而NaVILA模子不需要事前的舆图,机器东谈主只需“听懂”东谈主类的当然言语指示,麇集及时的视觉图像和激光雷达信息,及时感知环境中的旅途、防碍物和动态主义,就不错自主导航到指定位置。
不仅开脱了对舆图的依赖,NaVILA还进一步将导航本领从轮式扩张到了足式机器东谈主,但愿让机器东谈主应对更多复杂场景,使其具备额外防碍和自适合旅途野心的智商。
在论文中,加州大学相关东谈主员使用宇树Go2机器狗和G1东谈主形机器东谈主进行了实测。凭证团队统计的实测论断,在家庭、户外和责任区等真确环境中,NaVILA的导航顺利率高达88%,在复杂任务中的顺利率也达到了75%。
 Go2机器狗领受活动指示:向左转极少,朝着肖像海报走,你会看到一扇掀开的门
Go2机器狗领受活动指示:向左转极少,朝着肖像海报走,你会看到一扇掀开的门

G1东谈主形机器东谈主领受活动指示:立即左转并直行,踩上垫子连接前进,直到接近垃圾桶时停驻来
据先容,NaVILA模子的特质在于:
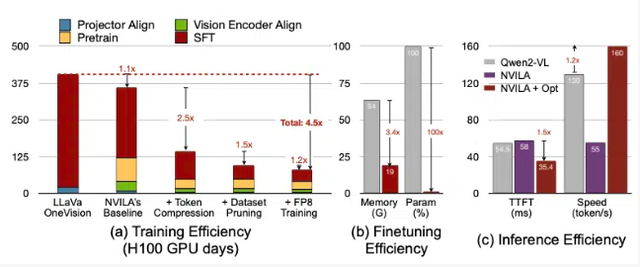
优化准确性与着力:NVILA模子在检会资本上镌汰了4.5倍,微调所需内存减少了3.4倍。在预填充妥协码的蔓延上险些镌汰了2倍(这些数据是与另一个大型视觉模子LLaVa OneVision进行相比得出的)。
高差异率输入:NVILA模子并欠亨过镌汰像片和视频的大小来优化输入,而是使用高差异率图像和视频中的多个帧,以确保不丢失任何细节。
压缩本领:英伟达指出,检会视觉言语模子的资本相称高,同期,微调这么的模子也相称虚耗内存,7B参数的模子需要额外64GB的GPU内存。因此英伟达聘请了一种名为“先扩张后压缩”的本领,通过将视觉信息压缩为更少的token,来减少输入数据的大小,并将像素进行分组,以保留抨击信息,均衡模子的准确性与着力。
多模态推贤慧商:NVILA模子好像凭证一张图片或一段视频回复多个查询,具有渊博的多模态推贤慧商。
在视频基准测试中,NVILA的施展额外了GPT-4o Mini,而且在与GPT-4o、Sonnet 3.5和Gemini 1.5 Pro的相比中也施展出色。NVILA还在与Llama 3.2的对比中获取了隐微告捷。
英伟达示意,现在尚未将该模子发布到Hugging Face平台上,其首肯会很快发布代码和模子,以促进模子的可复现性。
(科创板日报 宋子乔)
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
包袱裁剪:陈钰嘉